
A couple of weeks ago I released version 0.9 of the
jiraSOAP gem. jiraSOAP
0.9 is a milestone release for a few reasons, namely stability and
motivation. Stability, I think, is a reflection of my journey from
knowing little Ruby to being to pass myself off as knowing a thing or
two. This blog is about an adventure I had with developing
jiraSOAP.
A Little History
jiraSOAP is my first real ruby project and it was how I learned ruby
basics. My earlier experiences with ruby were small scripts to access
the bug tracker at work and I was using a gem called
jira4r to communicate with the
bug tracker. This gem was limited in a few ways that became very
irritating. It had no APIs from JIRA 4.x; the API it did expose was
ugly and inflexible; and the gem does not run on Ruby 1.9 and thus
could not run on MacRuby, which is a technology that my boss suggested
looking into.
At the time, JIRA was beginning to develop a REST API, but it was pre-alpha quality. The available resources were limited and read-only. On the other hand the still supported, but not actively developed, SOAP interface had APIs for almost everything.
Enter handsoap, a gem that promised an easy way to make a custom wrapper around a SOAP API that would be very fast. As it turns out, the speed part was overly optimistic, but I’ll get to that later. The important feature was that I could customize the API that I provided instead of simply generating something from the WSDL.
After a couple of weeks of playing with the library (it was far from
my primary concern at work), I had a working predecessor to
jiraSOAP. At this point I asked my boss if we could open source my
work; that way I would work on it more after hours and other people
could use and hopefully contribute to the project as well.
jiraSOAP’s Early OSS Days
The early days were hectic, I was pretty much rewriting jiraSOAP for
each release as I learned new things. I even had a silly contribution
policy warning people about contributions being unlikely to apply
cleanly.
Part of the problem was that the
recommended practices
for writing the SOAP client were about as vague as an East Texas
software patent, or at least the step about refactoring was. I can’t
blame handsoap for that problem, it was my first real ruby project
and I was still figuring a lot things out.
The logic for building messages was pretty clear and simple, but the the parsing logic required a relatively large amount of code from me. It was the parsing logic that was changing often due to refactoring with the goal of being cleaner and faster.
How Slow Was It?
handsoap claims to be faster because it can use C
extensions for HTTP communication and XML parsing, they even supply
some
benchmarks
in the README, though they qualify the benchmarks as being a little
unfair.
I guess the unfair part is that those numbers were not jiving with my personal experience; everything felt much slower than advertised. When I looked into it, I found that their benchmark code didn’t actually do any parsing!
Inspired by "ZOMG WHY IS THIS CODE SO SLOW?", I began my own investigation into why my gem was slow. Though, in my case I was working with a smaller and more sane code base.
Step 1 is figuring out what to measure and then step 2 is making the
baseline measurements. Since I supplied most of the parsing logic, I
figured that I should measure parsing time. I chose to measure parse
time for Issue objects since it is the most common type of object
to work with; but it is also the largest type, weighing in at 21
attributes, including collections of other data structures that need
to be parsed.
Before I get to how the measurements were made, I should mention that when I originally performed benchmarks that I was not very rigorous about collecting data. For the sake of this blog post I went back in time and benchmarked things properly. I say properly, but I really mean "good enough" for my purposes.
Since I wanted to measure just parsing time, I needed to change the
jiraSOAP code base a little. The gist shows how to modify the
jiraSOAP 0.9 code, but the changes needed for an older version are
almost the same:
As a baseline I measured
jira4r-jh, a recent
fork that includes an API that I wanted to use, but the changes needed
for measurement happened in soap4r, a dependency:
Instead of using benchmark or minitest, I opted to just write a
small script:
The oddity there is that I average a larger sample set for a smaller
number of issues because I am trying to avoid outliers from the GC
kicking in. I didn’t want to stop the GC as that seemed too
unrealistic, but I did give a 1 second sleep period between
benchmarking runs. Since I am trying to show the difference in
performance between versions, I don’t think it will matter as long as
I am consistent and the numbers don’t end up being very close
together.
Due to differences in how I patched the projects, the benchmark script
for jira4r is a little different, I won’t embed it here, but it’s in
the gist with everything else.
If you are familiar with the JIRA version of SQL, you can see that I
am always using the same set of issues for each test run; and the 1000
issues that were used take up 4.4 MB on disk when dumped to a file.
Benchmarks on my 2.4 GHz C2D MacBook Pro running OS X Lion. jiraSOAP
benchmarks were run using Ruby 1.9.3preview1 and MacRuby 0.10;
jira4r benchmarks were run using Ruby 1.8.7-p249.
The Numbers
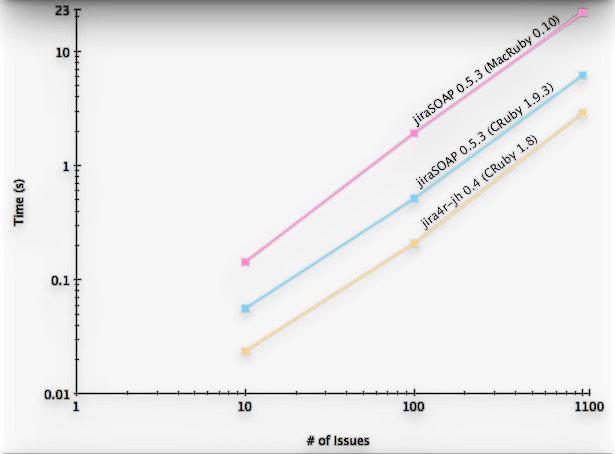
WHAT. THE. FRAK?! jiraSOAP was more than 2x slower than jira4r with
CRuby; with MacRuby the the performance really bad—a whopping 7x
slower than jira4r and more than 3x slower than the equivalent code
running on CRuby.
Experienced MacRuby users will probably suggest that such low
performance is a result of lots and lots of memory
allocations—programs that allocate a lot of memory will usually be
slower on MacRuby. Using that intuition I began tracing through the
parsing logic and found that the problem was how each Issue was
being initialized.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
A quick glance at the code will tell you that it has to dup each
array and each element of the array for each call. But wait, it gets
worse! Those strings are used in an the XPath query which is run on
the same XML fragment for each attribute. The symbol elements are then
used as the name of the transformer to be used on the XML node’s inner
text; the data transformers could be simple and just take the
string from the inner text, or end up triggering the
initialization of more objects that needed to be parsed
(#to_objects), or it could initialize an array of Nazi soldiers
(#to_ss).
So for each issue, the virtual machine was constantly reallocating a lot of constant data, and re-walking the XML fragment for each XPath query. That makes two separate problems that should be fixable and which will undoubtedly improve performance and get rid of some repetitive code.
Plan of Attack
To fix iterating through the XML fragment for each attribute, I had to stop using XPath. While XPath is easier to use it was a bad fit in the first place since data from every node of the fragment was being used. I’d say that putting XPath in the recommended steps without a caveat was a bit misleading.
Some quick research revealed that the best choice for this problem was a pull parser since it only iterates over the fragment once. The important thing to note here is that this change will cause the logic to switch around—instead of getting each attribute to ask for some XML it will now get each XML node to ask for an attribute. What makes this faster is that asking for a node required the use of XPath whereas asking for an attribute could be as simple as a hash look up.
Given that the XML should be highly structured, I could have iterated through both the XML nodes and an array with the attribute names to just match the nodes and attributes up; however I was not to sure on the ordering of nodes with respect to sub-classing, perhaps it was in alphabetical order, but I would have to go through the WSDL for each version of JIRA that I wanted to support. Since I didn’t want to do that took a potential performance hit and used a hash where the node name corresponded to a key.
Using this new strategy, the parsing logic was totally generic and I refactored initialization of all XML entities to a common method:
1 2 3 4 5 6 7 | |
Each class had its own parse map, and you can see from the code
snippet. By declaring attributes using a data-mapper style of class
method, the maps were built up for each class. The interesting part
was getting inheritance working for parse maps; at first I had the
obvious solution which looked a bit hacky but then I learned about
some rarely used methods in ruby.
Ruby’s Less Frequently Used Metaprogramming Callbacks
Class#inherited, Module#included, and Module#extended are
callbacks which are executed each time a Class/Module is subclassed,
included, or extended. You can override the default implementation,
which is an empty method, to provide custom inheritance/mixin rules.
This turns logic that looks like this:
1 2 3 4 5 | |
into a one line method like this:
1 2 3 | |
Which I think is much nicer since it separates the logic of inheriting a parse map from adding a new property. It is also faster since it does not need to check if the value is already initialized which is a savings of a couple hundred checks at boot time.
I found out about this callback when I was going over the
HotCocoa::Behaviors
module, but I have since also found out that it is the technique used
by minitest in order to keep track of which classes have tests.
Jumping Back To The Numbers
With the new parsing logic, how do the two gems stack up?
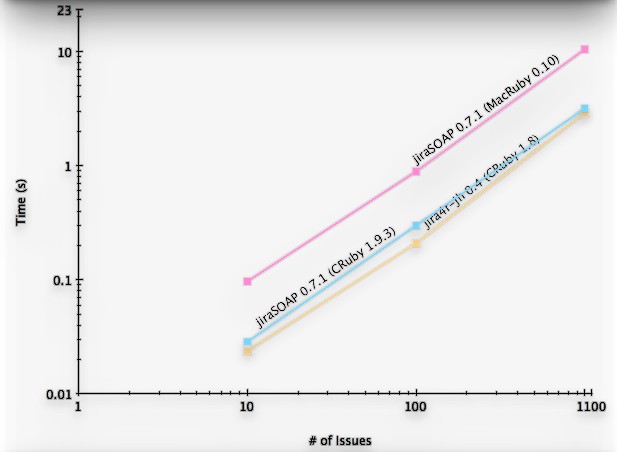
About a 2x improvement! CRuby jiraSOAP is just a bit slower
than jira4r, and MacRuby jiraSOAP is about as fast as CRuby
jiraSOAP was before the change.
Given the performance gap, I still suspected the issue is that there
are too many allocations somewhere, but probably not in my code
anymore. That is when I started looking into handsoap’s source code
to see what goes on when I parse XML.
It turns out that their parsing abstraction was the gold mine I should have been looking for earlier. Specifically, their method for getting the inner text of an XML node, #to_s.
That method does a bit of work to handle cases that are not relevant to
jiraSOAP, but that detail is very minor when compared to calling
Node#serialize
in nokogiri which ends up unpacking two options hashes before it
gets to the point of extracting the inner text, which then returns to
handsoap so that it can run 5 chained #gsub calls.
The real kicker is that all the data transformers call#to_s first to
get the nodes inner text. For an issue with 21 attributes, including
nested structures, that is at least 21 calls to #to_s which
allocates, among other things, the following:
#to_s- a Hash for options with a Symbol to String key-value pair (3)
- 5
gsubcalls with literal String arguments that need to be duped (15)
#serialize- a String to setup the encoding information (1)
- a StringIO to buffer the inner text into the string that was setup before (1)
#write_to- a String will have to be duped for the
indent_textoption in this case (1) - a SaveOptions object (1)
- a String that will be created by
indent_text * indent_times(1)
- a String will have to be duped for the
That is at least 23 unneeded allocations per call of #to_s, which
is 483 allocations per issue object and 483,000 allocations for the
1000 issue sample.
Keep in mind that that number is for the minimum number of attributes;
an issue has two arrays of Version objects, one for affected
versions and one for fix versions, and each version has 6 attributes;
issues also have an array of CustomFieldValue objects with 3
attributes each; and issues also have an array of attachment name
strings. Realistically, most issues will have an affects version and
probably a fix version; many databases also use custom field.
483,000 allocations is actually a conservative estimate and the real
number of wasteful allocations is is well over 500,000.
Fixing The Problem
Fixing things in handsoap was a possibility, but I had already
opened a pull request in which the handsoap devs were responding
too infrequently. I decided that handsoap was unfairly allocated
some resources that I wanted and I took upon myself to fix the problem
by liberating the oppressed methods—I went freedom patching.
As mentioned earlier, I didn’t need code to handle any of the special
cases. I also think that calling gsub to swap out escaped characters
is a waste since the data will end up in an HTML document more often
than not.
After checking, I found that I could just call Node#content to get the inner text of an XML node. That method doesn’t do any of unnecessary work that I outlined earlier, it doesn’t even enforce an encoding.
Newest Numbers
How do the performance numbers look after bypassing the extraneous
code paths of handsoap?
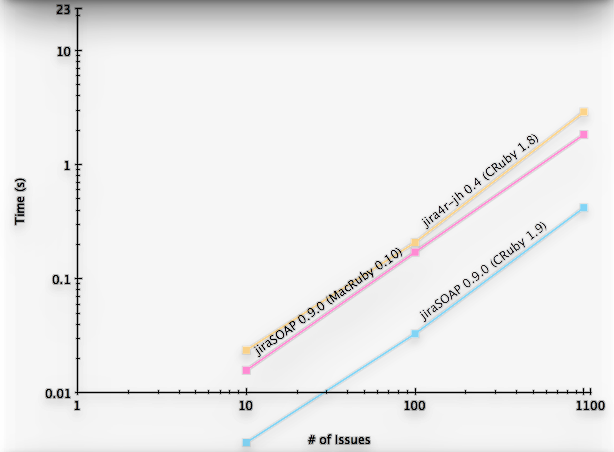
Really good! jiraSOAP on CRuby now runs so much faster that the
scaling for the graphs is all messed up. Even jiraSOAP on MacRuby is
now faster than jira4r.
I also haven’t had any bugs logged related to encoding problems or escaped characters, so I think this is a big win. I even went and benchmarked past 1000 issues.
How Does It Scale?
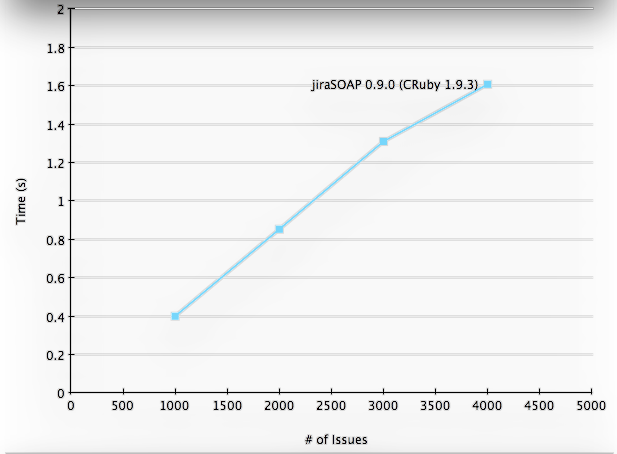
jiraSOAP now parses ~2250 issues/s, which is ~10MB/s, which I
think is pretty good. It also looks like the new lazy-sweep GC changes
in ruby 1.9.3 kick in somewhere between 3000-4000 issues which is very
cool.
The parsing can still get faster without resorting to C (nokogiri excepted); there are other solutions I have not tried yet because I haven’t had the time lately.
One such solution would be to cache the XML fragment and only parse it on demand. I would have to go back to XPath in this case, but since parsing is not done until needed it will get the standard laziness trade off of maybe never having to parse the XML and saving potentially many allocations.
Benchmarking such a change would be more challenging since it would
need to take into account a much larger sample of the different ways
in which people are using jiraSOAP; how man attributes are used
normally and how often?
Then there is the memory-time trade off to consider, the XML document is, at some level, a very large string, which is not nearly as memory efficient as the structures the data would be parsed into and would be expensive to keep around for a long period of time.
The lack of understanding on how other people use the gem is the reason why it would be difficult to tell whether or not it would be faster in the general case or at least worth the memory trade off. I know at least one person was using the gem as part of a rails app, but I don’t know if it was a main component or simply a way to log bugs when errors occurred.
I could at least go as far as to find the threshold at which it becomes worthwhile by actually implementing the change, but I don’t have the time right now and at this point the performance bottleneck is probably not parsing anymore.
Next Steps
The real performance bottleneck now is the use of net/http for the
networking layer. With CRuby you can easily tell handsoap to use a
different back end for HTTP communication. curb is handsoap’s
recommended back end and is much faster than net/http, but it is not
compatible with MacRuby which is why I changed the default to
net/http.
If you are using CRuby then you are better off switching to curb or
httpclient after loading jiraSOAP:
1 2 3 4 | |
You can also use eventmachine with handsoap, but it will not work
with jiraSOAP out of the box, you would need to reimplement the 4
private methods in lib/jiraSOAP/api.rb.
In the future I think I will be able to release the gem once for each
RUBY_ENGINE so that each ruby can have proper defaults. It would
also be nice to have a MacRuby specific back end that uses Cocoa for
the networking layer.
Though, by this time next year I expect that the JIRA REST API will
have caught up to the SOAP API and jiraSOAP will become
obsolete. So I don’t think I will be spending too much more time on
this project. Besides, jiraSOAP now implements 99% of the API that I
care about and the implementation is simple enough and stable enough
to have other APIs easily added by users who want them.